
Deepseek V4 with Strix: a quick test
Deepseek released V4 yesterday in two variants. V4 Pro has 1.6T total parameters with 49B active, while V4 Flash is the smaller, faster, cheaper sibling with 284B total and 13B active. In the release notes, the company claims that V4 Pro rivals the world’s best closed-source models in reasoning and leads all open models on agentic coding benchmarks. It also says that V4 Flash comes surprisingly close despite its smaller size and can match Pro on simpler agentic tasks.
Those are exactly the kinds of claims worth testing, so I wanted to see how both models hold up in my local lab setup and how they compare with the other models I have tested recently.
Test setup
I tested both models using the exact methodology described in my Agentic AI pentesting with Strix: results from 18 LLM models post. In short:
- The target was my test server, which contains 14 known vulnerabilities.
- I ran both models through Strix v0.8.3.
- I ran three full tests for each model.
- The final score is the average of the summed CVSS scores for all vulnerabilities found in each run.
- The final cost is the average cost per run, with both models accessed through OpenRouter.
Results in context
First, here is how both models compare with the other models I have already tested.
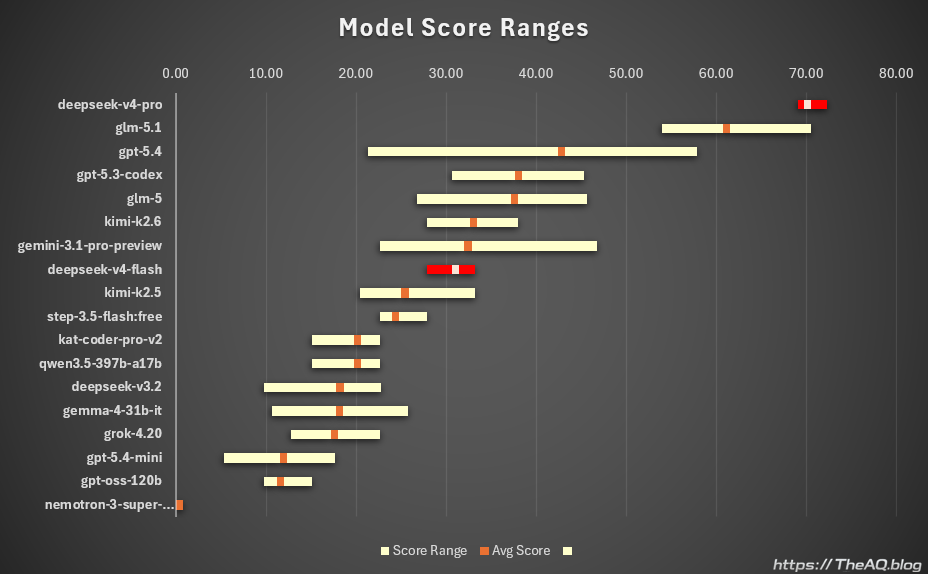
The first chart shows the average score and the range from the lowest-scoring run to the highest-scoring run:
- Deepseek V4 Pro averaged 70.10, with runs ranging from 69.0 to 72.3
- Deepseek V4 Flash averaged 31.03, with runs ranging from 27.9 to 33.2
The second chart compares score against average cost per run. Score is on the Y-axis and average cost per run is on the X-axis. The average cost was 26.04 USD for Deepseek V4 Pro and 1.00 USD for Deepseek V4 Flash.
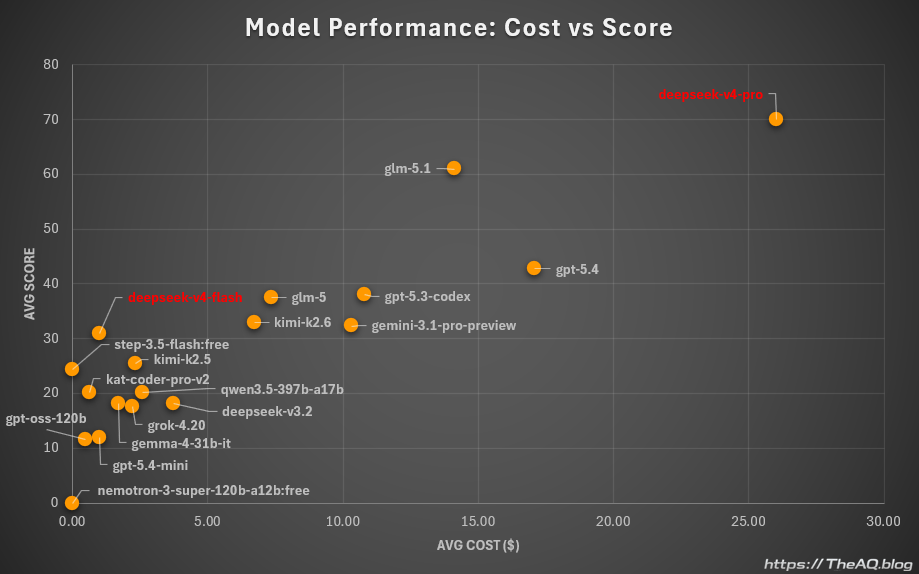
Deepseek V4 Pro: best score, highest cost
With an average score of 70.1, Deepseek V4 Pro is the strongest model I have tested in this lab so far (that said, I have not tested GPT-5.5 yet, and there is a good chance it will take the top spot once I do). The trade-off is cost: at 26.04 USD per run, it is also the most expensive model I completed end-to-end, excluding tests with Anthropic models that I stopped early because they became too costly.
If your priority is maximum capability in this workflow and cost is a secondary concern, this is a model worth considering. For my own routine testing, I will probably stick with GLM 5.1 because the performance gap is small enough that paying roughly half as much still feels like the better trade-off.
Deepseek V4 Flash: strong value for quick checks
With an average score of 31.03 and an average cost of 1.00 USD per run, Deepseek V4 Flash becomes my new go-to model for quick tests. It is also the strongest model I have tested so far among models that could plausibly be self-hosted on sufficiently beefy home hardware.
Even when accessed through a hosted endpoint, it delivers performance roughly in the Kimi K2.6 range at a fraction of the price.