
How much better is Strix 1.0? Results from a small rerun
It has been a while since my last blog post, but I definitely haven’t stopped playing with AI-assisted security tools. Summer is here, and my schedule is finally a little less crowded, so I’m planning to write a few blog posts about what I’ve learned lately.
This post should be short and to the point. After a few months in its v0.x phase, Strix recently reached adulthood with the release of version 1.0. Since I ran quite a few tests with Strix v0.8.3 in the past, I was curious whether the improvements in Strix v1.0.4 justified the major-version bump.
Test setup
I decided to rerun part of the tests I previously ran with Strix v0.8.3 using Strix v1.0.4. I selected two LLM models for the rerun: DeepSeek V4 Flash and GLM-5.1.
To keep the results comparable, I kept the test scenario unchanged:
- I tested against a live lab instance of my own deliberately vulnerable server, which contains 14 intentionally planted vulnerabilities.
- The test score was calculated by summing the CVSS base scores for all unique vulnerabilities found during a run. I know CVSS is not additive; this is a simplified benchmark proxy, not a real-world risk model, but it gives me a consistent way to compare repeated runs.
- For each LLM model, I ran the test three times. The final score is the average of those three runs.
Benchmark results
Here are the results for both models. Each table shows selected metrics from the earlier Strix v0.8.3 test and the new Strix v1.0.4 rerun.
DeepSeek V4 Flash
| Strix Version | Avg. Score | Avg. Cost | Avg. Tokens Used | Avg. Tool Calls |
|---|---|---|---|---|
| v0.8.3 | 31.0 | $1.0 | 22.7 M | 333 |
| v1.0.4 | 42.0 | $1.4 | 26.8 M | 520 |
GLM 5.1
| Strix Version | Avg. Score | Avg. Cost | Avg. Tokens Used | Avg. Tool Calls |
|---|---|---|---|---|
| v0.8.3 | 61.1 | $14.1 | 30.8 M | 393 |
| v1.0.4 | 70.6 | $12.2 | 49.9 M | 628 |
Charts
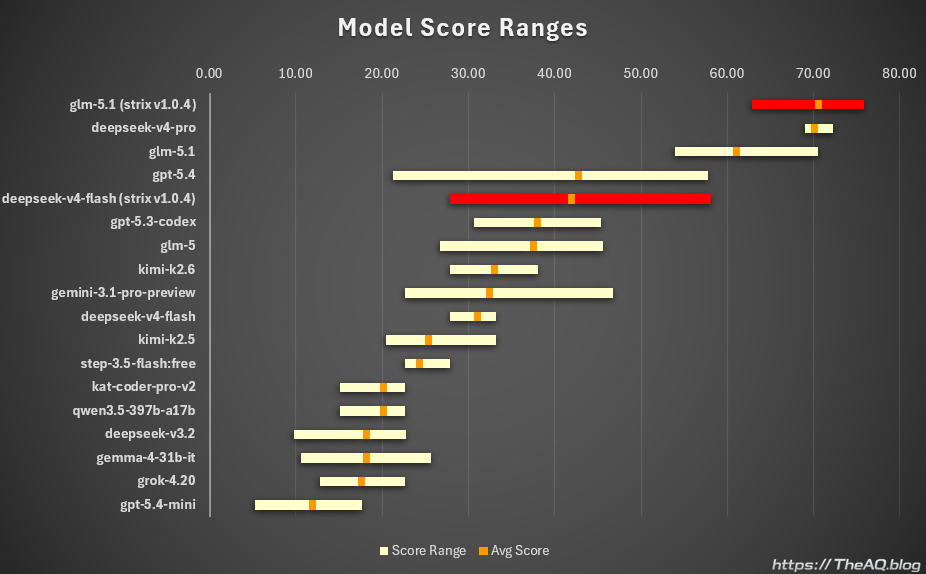
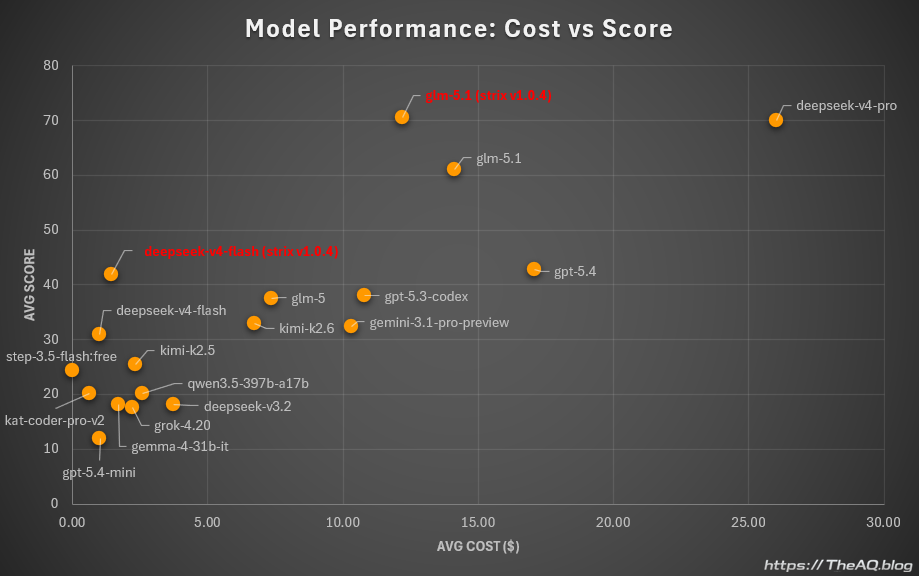
Here are some visualisations of these results, so you can compare them with the results from other LLMs that I tested previously. The older results in these charts were all produced with Strix v0.8.3; I just added results from tests with the latest Strix version and highlighted them in red.
The first chart shows the tested LLMs, sorted by average score from highest to lowest. Alongside the average, shown as the orange point on each line, you can also see each model’s score range across all three test runs.
The second chart (and I appreciate that it’s already a bit crowded) shows the average score alongside the average cost per test for each LLM.
What the numbers suggest
The average score for both models increased by about 10 points in Strix v1.0.4. That is A LOT.
For context, here are score differences I previously measured between different model versions:
- Kimi K2.5 -> Kimi K2.6 = 7.6-point increase (from 25.4 to 33.0)
- DeepSeek V3.2 -> DeepSeek V4 Flash = 12.8-point increase (18.2 -> 31.0)
- GLM 5 -> GLM 5.1 = 23.5-point increase (37.6 -> 61.1)
I know this comparison is a bit of a stretch, but still: the improvement I got just by updating Strix from v0.8.3 to v1.0.4 was in the same ballpark as some model-version upgrades.
The token counts and tool-call counts hint at where the improvement came from. Strix v1.0.4 appears to push the model through more exploration, validation, and tool use than v0.8.3. For me, that is what a good agentic pentest harness is about: it cannot make the underlying model smarter, but it can help squeeze more practical testing value out of the model’s existing capabilities.
A higher token count usually means a higher test cost. Surprisingly, that is not obvious from my results: the average cost of a single test is roughly similar across both Strix versions. I use OpenRouter as my LLM provider, and many factors outside my control can influence the final cost, such as which sub-provider gets selected or how many tokens are cached, so take my cost numbers with a grain of salt. The general logic is still obvious: more tokens usually means higher cost.
Rough edges in Strix 1.0.4
Strix’s internals were significantly rewritten in version 1.0, and there are still a few places that need polish.
I found Strix somewhat fragile when it encountered recoverable upstream errors. For example, a test could fail when the connection to the LLM hosting backend was momentarily lost, or when the model hallucinated or misspelled the name of a tool it wanted to call. I summarized my experience in this GitHub issue. In most cases, retrying the LLM call should handle these failures gracefully, so retry logic should cover much of this. I even opened a PR with a change that fixed this issue for me in my fork.
The estimated per-run cost reported by Strix was also way off during my tests, but that is a minor issue.
As a former developer, I have some sympathy for issues like this, so they didn’t spoil the fun for me, but they are worth knowing about. If you are a reader from the future, they may already be fixed, as these are not fundamental design problems.
Conclusion
I didn’t expect such a big performance increase in Strix v1.0.4. I expected only a barely measurable improvement, somewhere just above the statistical noise of my testing.
So was I surprised by this big increase? Yes and no.
Lately, I have spent some time researching open source hackbots, or AI-assisted security tools. The research was not just about running tests or reading READMEs. I used my 20+ years of software development experience, read through the source code, and compared how these tools approach different phases of testing: planning, attack-surface discovery, tool orchestration, evidence collection, and finding validation. I’d like to turn that work into a short series of blog posts (please let me know if you are interested), but the outcome of my research was quite clear: Strix is arguably the most thought-through product in this category, with the most complex approach to the testing process. And I have hard data for this claim. I can prove it. I even have PowerPoint slides for it! 😄
Looking at it from that perspective, I am not actually all that surprised by the big step forward it made in v1.0.4. From what I saw in the source code, these guys know what they are doing.
I’m not sure how much further Strix can improve, but I will definitely be watching it closely.